Dplyr and Writing Scripts
Yanru Xing
Adapted from R for Data Science by Hadley Wichkam and Garrett Grolemund
Download slides here
tidyverse = A collection of R packages
Package ‘dplyr’
A Grammar of Data Manipulation
Description A fast, consistent tool for working with data frame like objects, both in memory and out of memory.
#install.packages("nycflights13")
#install.packages("tidyverse")
library(tidyverse)
library(nycflights13)
nycflights13::flights #This data frame contains all 336,776 flights that departed from New York City in 2013## # A tibble: 336,776 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2. 830
## 2 2013 1 1 533 529 4. 850
## 3 2013 1 1 542 540 2. 923
## 4 2013 1 1 544 545 -1. 1004
## 5 2013 1 1 554 600 -6. 812
## 6 2013 1 1 554 558 -4. 740
## 7 2013 1 1 555 600 -5. 913
## 8 2013 1 1 557 600 -3. 709
## 9 2013 1 1 557 600 -3. 838
## 10 2013 1 1 558 600 -2. 753
## # ... with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>flights## # A tibble: 336,776 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2. 830
## 2 2013 1 1 533 529 4. 850
## 3 2013 1 1 542 540 2. 923
## 4 2013 1 1 544 545 -1. 1004
## 5 2013 1 1 554 600 -6. 812
## 6 2013 1 1 554 558 -4. 740
## 7 2013 1 1 555 600 -5. 913
## 8 2013 1 1 557 600 -3. 709
## 9 2013 1 1 557 600 -3. 838
## 10 2013 1 1 558 600 -2. 753
## # ... with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>#View(flights) #To see the whole dataset, which will open the dataset in the RStudio viewer.Five key dplyr functions that allow you to solve the vast majority of your data manipulation challenges:
- Pick observations by their values (filter()).
- Reorder the rows (arrange()).
- Pick variables by their names (select()).
- Create new variables with functions of existing variables (mutate()).
- Collapse many values down to a single summary (summarise()).
Filter Rows with filter()
filter() allows you to subset observations based on their values. The first argument is the name of the data frame. The second and subsequent arguments are the expressions that filter the data frame. For example, we can select all flights on January 1st with:
filter(flights, month == 1, day == 1)## # A tibble: 842 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2. 830
## 2 2013 1 1 533 529 4. 850
## 3 2013 1 1 542 540 2. 923
## 4 2013 1 1 544 545 -1. 1004
## 5 2013 1 1 554 600 -6. 812
## 6 2013 1 1 554 558 -4. 740
## 7 2013 1 1 555 600 -5. 913
## 8 2013 1 1 557 600 -3. 709
## 9 2013 1 1 557 600 -3. 838
## 10 2013 1 1 558 600 -2. 753
## # ... with 832 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>jan1 <- filter(flights, month == 1, day == 1)
jan1## # A tibble: 842 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2. 830
## 2 2013 1 1 533 529 4. 850
## 3 2013 1 1 542 540 2. 923
## 4 2013 1 1 544 545 -1. 1004
## 5 2013 1 1 554 600 -6. 812
## 6 2013 1 1 554 558 -4. 740
## 7 2013 1 1 555 600 -5. 913
## 8 2013 1 1 557 600 -3. 709
## 9 2013 1 1 557 600 -3. 838
## 10 2013 1 1 558 600 -2. 753
## # ... with 832 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm># (dec25 <- filter(flights, month == 12, day == 25)) #R either prints out the results, or saves them to a variable. If you want to do both, you can wrap the assignment in parenthesesComparison Operators
# There’s another common problem you might encounter when using ==: floating point numbers. These results might surprise you!
sqrt(2) ^ 2 == 2## [1] FALSE1 / 49 * 49 == 1## [1] FALSE#Computers use finite precision arithmetic (they obviously can’t store an infinite number of digits!) so remember that every number you see is an approximation. Instead of relying on ==, use near():
near(sqrt(2) ^ 2, 2)## [1] TRUEnear(1 / 49 * 49, 1)## [1] TRUELogical Operators
# The following code finds all flights that departed in November or December:
filter(flights, month == 11 | month == 12)## # A tibble: 55,403 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 11 1 5 2359 6. 352
## 2 2013 11 1 35 2250 105. 123
## 3 2013 11 1 455 500 -5. 641
## 4 2013 11 1 539 545 -6. 856
## 5 2013 11 1 542 545 -3. 831
## 6 2013 11 1 549 600 -11. 912
## 7 2013 11 1 550 600 -10. 705
## 8 2013 11 1 554 600 -6. 659
## 9 2013 11 1 554 600 -6. 826
## 10 2013 11 1 554 600 -6. 749
## # ... with 55,393 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>nov_dec <- filter(flights, month %in% c(11, 12))
nov_dec## # A tibble: 55,403 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 11 1 5 2359 6. 352
## 2 2013 11 1 35 2250 105. 123
## 3 2013 11 1 455 500 -5. 641
## 4 2013 11 1 539 545 -6. 856
## 5 2013 11 1 542 545 -3. 831
## 6 2013 11 1 549 600 -11. 912
## 7 2013 11 1 550 600 -10. 705
## 8 2013 11 1 554 600 -6. 659
## 9 2013 11 1 554 600 -6. 826
## 10 2013 11 1 554 600 -6. 749
## # ... with 55,393 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm># Find flights that weren’t delayed (on arrival or departure) by more than two hours, you could use either of the following two filters:
filter(flights, !(arr_delay > 120 | dep_delay > 120))## # A tibble: 316,050 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2. 830
## 2 2013 1 1 533 529 4. 850
## 3 2013 1 1 542 540 2. 923
## 4 2013 1 1 544 545 -1. 1004
## 5 2013 1 1 554 600 -6. 812
## 6 2013 1 1 554 558 -4. 740
## 7 2013 1 1 555 600 -5. 913
## 8 2013 1 1 557 600 -3. 709
## 9 2013 1 1 557 600 -3. 838
## 10 2013 1 1 558 600 -2. 753
## # ... with 316,040 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>filter(flights, arr_delay <= 120, dep_delay <= 120)## # A tibble: 316,050 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2. 830
## 2 2013 1 1 533 529 4. 850
## 3 2013 1 1 542 540 2. 923
## 4 2013 1 1 544 545 -1. 1004
## 5 2013 1 1 554 600 -6. 812
## 6 2013 1 1 554 558 -4. 740
## 7 2013 1 1 555 600 -5. 913
## 8 2013 1 1 557 600 -3. 709
## 9 2013 1 1 557 600 -3. 838
## 10 2013 1 1 558 600 -2. 753
## # ... with 316,040 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>One important feature of R that can make comparison tricky are missing values, or NAs (“not availables”). NA represents an unknown value so missing values are “contagious”: almost any operation involving an unknown value will also be unknown.
NA > 5## [1] NA10 == NA## [1] NANA + 10## [1] NANA / 2## [1] NANA == NA## [1] NAx <- NA
y <- NA
x == y## [1] NAis.na(x) # Function to determine is a value is missing## [1] TRUEfilter() & missing values
df <- tibble(x = c(1, NA, 3))
filter(df, x > 1)## # A tibble: 1 x 1
## x
## <dbl>
## 1 3.filter(df, is.na(x) | x > 1)## # A tibble: 2 x 1
## x
## <dbl>
## 1 NA
## 2 3.filter() exercises
# 1. Find all flights that:
# 1. Had an arrival delay of two or more hours
filter(flights, (arr_delay > 120))## # A tibble: 10,034 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 811 630 101. 1047
## 2 2013 1 1 848 1835 853. 1001
## 3 2013 1 1 957 733 144. 1056
## 4 2013 1 1 1114 900 134. 1447
## 5 2013 1 1 1505 1310 115. 1638
## 6 2013 1 1 1525 1340 105. 1831
## 7 2013 1 1 1549 1445 64. 1912
## 8 2013 1 1 1558 1359 119. 1718
## 9 2013 1 1 1732 1630 62. 2028
## 10 2013 1 1 1803 1620 103. 2008
## # ... with 10,024 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm># 2. Flew to Houston (IAH or HOU)
filter(flights, (dest == "IAH" | dest == "HOU"))## # A tibble: 9,313 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2. 830
## 2 2013 1 1 533 529 4. 850
## 3 2013 1 1 623 627 -4. 933
## 4 2013 1 1 728 732 -4. 1041
## 5 2013 1 1 739 739 0. 1104
## 6 2013 1 1 908 908 0. 1228
## 7 2013 1 1 1028 1026 2. 1350
## 8 2013 1 1 1044 1045 -1. 1352
## 9 2013 1 1 1114 900 134. 1447
## 10 2013 1 1 1205 1200 5. 1503
## # ... with 9,303 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm># 3. Were operated by United, American, or Delta
filter(flights, (carrier %in% c("UA","AA","DL")))## # A tibble: 139,504 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2. 830
## 2 2013 1 1 533 529 4. 850
## 3 2013 1 1 542 540 2. 923
## 4 2013 1 1 554 600 -6. 812
## 5 2013 1 1 554 558 -4. 740
## 6 2013 1 1 558 600 -2. 753
## 7 2013 1 1 558 600 -2. 924
## 8 2013 1 1 558 600 -2. 923
## 9 2013 1 1 559 600 -1. 941
## 10 2013 1 1 559 600 -1. 854
## # ... with 139,494 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm># 4. Departed in summer (July, August, and September)
filter(flights, (month == 7 | month == 8 | month == 9 ))## # A tibble: 86,326 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 7 1 1 2029 212. 236
## 2 2013 7 1 2 2359 3. 344
## 3 2013 7 1 29 2245 104. 151
## 4 2013 7 1 43 2130 193. 322
## 5 2013 7 1 44 2150 174. 300
## 6 2013 7 1 46 2051 235. 304
## 7 2013 7 1 48 2001 287. 308
## 8 2013 7 1 58 2155 183. 335
## 9 2013 7 1 100 2146 194. 327
## 10 2013 7 1 100 2245 135. 337
## # ... with 86,316 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm># 5. Arrived more than two hours late, but didn’t leave late
filter(flights, (arr_delay > 120 & dep_delay <= 0))## # A tibble: 29 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 27 1419 1420 -1. 1754
## 2 2013 10 7 1350 1350 0. 1736
## 3 2013 10 7 1357 1359 -2. 1858
## 4 2013 10 16 657 700 -3. 1258
## 5 2013 11 1 658 700 -2. 1329
## 6 2013 3 18 1844 1847 -3. 39
## 7 2013 4 17 1635 1640 -5. 2049
## 8 2013 4 18 558 600 -2. 1149
## 9 2013 4 18 655 700 -5. 1213
## 10 2013 5 22 1827 1830 -3. 2217
## # ... with 19 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm># 6. Were delayed by at least an hour, but made up over 30 minutes in flight
# 7. Departed between midnight and 6am (inclusive)
filter(flights, (dep_time >= 1 & dep_time <= 600)) ## # A tibble: 9,344 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2. 830
## 2 2013 1 1 533 529 4. 850
## 3 2013 1 1 542 540 2. 923
## 4 2013 1 1 544 545 -1. 1004
## 5 2013 1 1 554 600 -6. 812
## 6 2013 1 1 554 558 -4. 740
## 7 2013 1 1 555 600 -5. 913
## 8 2013 1 1 557 600 -3. 709
## 9 2013 1 1 557 600 -3. 838
## 10 2013 1 1 558 600 -2. 753
## # ... with 9,334 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm># 2. Another useful dplyr filtering helper is between(). What does it do? Can you use it to simplify the code needed to answer the previous challenges?
# 3. How many flights have a missing dep_time? What other variables are missing? What might these rows represent?
# 4. Why is NA ^ 0 not missing? Why is NA | TRUE not missing? Why is FALSE & NA not missing? Can you figure out the general rule? (NA * 0 is a tricky counterexample!)Arrange rows with arrange()
arrange() works similarly to filter() except that instead of selecting rows, it changes their order. It takes a data frame and a set of column names (or more complicated expressions) to order by.
# If you provide more than one column name, each additional column will be used to break ties in the values of preceding columns:
arrange(flights, year, month, day)## # A tibble: 336,776 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2. 830
## 2 2013 1 1 533 529 4. 850
## 3 2013 1 1 542 540 2. 923
## 4 2013 1 1 544 545 -1. 1004
## 5 2013 1 1 554 600 -6. 812
## 6 2013 1 1 554 558 -4. 740
## 7 2013 1 1 555 600 -5. 913
## 8 2013 1 1 557 600 -3. 709
## 9 2013 1 1 557 600 -3. 838
## 10 2013 1 1 558 600 -2. 753
## # ... with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm># Use desc() to re-order by a column in descending order:
arrange(flights, desc(dep_delay))## # A tibble: 336,776 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 9 641 900 1301. 1242
## 2 2013 6 15 1432 1935 1137. 1607
## 3 2013 1 10 1121 1635 1126. 1239
## 4 2013 9 20 1139 1845 1014. 1457
## 5 2013 7 22 845 1600 1005. 1044
## 6 2013 4 10 1100 1900 960. 1342
## 7 2013 3 17 2321 810 911. 135
## 8 2013 6 27 959 1900 899. 1236
## 9 2013 7 22 2257 759 898. 121
## 10 2013 12 5 756 1700 896. 1058
## # ... with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>Missing values are always sorted at the end:
df <- tibble(x = c(5, 2, NA))
arrange(df, x)## # A tibble: 3 x 1
## x
## <dbl>
## 1 2.
## 2 5.
## 3 NAarrange(df, desc(x))## # A tibble: 3 x 1
## x
## <dbl>
## 1 5.
## 2 2.
## 3 NAExercises
1. How could you use arrange() to sort all missing values to the start? (Hint: use is.na()).
2. Sort flights to find the most delayed flights. Find the flights that left earliest.
3. Sort flights to find the fastest flights.
4. Which flights travelled the longest? Which travelled the shortest?
Select Columns with select()
It’s not uncommon to get datasets with hundreds or even thousands of variables. In this case, the first challenge is often narrowing in on the variables you’re actually interested in.
select() allows you to rapidly zoom in on a useful subset using operations based on the names of the variables.
select()
# Select columns by name
select(flights, year, month, day)## # A tibble: 336,776 x 3
## year month day
## <int> <int> <int>
## 1 2013 1 1
## 2 2013 1 1
## 3 2013 1 1
## 4 2013 1 1
## 5 2013 1 1
## 6 2013 1 1
## 7 2013 1 1
## 8 2013 1 1
## 9 2013 1 1
## 10 2013 1 1
## # ... with 336,766 more rows# Select all columns between year and day (inclusive)
select(flights, year:day)## # A tibble: 336,776 x 3
## year month day
## <int> <int> <int>
## 1 2013 1 1
## 2 2013 1 1
## 3 2013 1 1
## 4 2013 1 1
## 5 2013 1 1
## 6 2013 1 1
## 7 2013 1 1
## 8 2013 1 1
## 9 2013 1 1
## 10 2013 1 1
## # ... with 336,766 more rows# Select all columns except those from year to day (inclusive)
select(flights, -(year:day))## # A tibble: 336,776 x 16
## dep_time sched_dep_time dep_delay arr_time sched_arr_time arr_delay
## <int> <int> <dbl> <int> <int> <dbl>
## 1 517 515 2. 830 819 11.
## 2 533 529 4. 850 830 20.
## 3 542 540 2. 923 850 33.
## 4 544 545 -1. 1004 1022 -18.
## 5 554 600 -6. 812 837 -25.
## 6 554 558 -4. 740 728 12.
## 7 555 600 -5. 913 854 19.
## 8 557 600 -3. 709 723 -14.
## 9 557 600 -3. 838 846 -8.
## 10 558 600 -2. 753 745 8.
## # ... with 336,766 more rows, and 10 more variables: carrier <chr>,
## # flight <int>, tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>,
## # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>There are a number of helper functions you can use within select():
starts_with(“abc”): matches names that begin with “abc”.
ends_with(“xyz”): matches names that end with “xyz”.
contains(“ijk”): matches names that contain “ijk”.
select(flights, starts_with("dep"))## # A tibble: 336,776 x 2
## dep_time dep_delay
## <int> <dbl>
## 1 517 2.
## 2 533 4.
## 3 542 2.
## 4 544 -1.
## 5 554 -6.
## 6 554 -4.
## 7 555 -5.
## 8 557 -3.
## 9 557 -3.
## 10 558 -2.
## # ... with 336,766 more rowsselect(flights, ends_with("lay"))## # A tibble: 336,776 x 2
## dep_delay arr_delay
## <dbl> <dbl>
## 1 2. 11.
## 2 4. 20.
## 3 2. 33.
## 4 -1. -18.
## 5 -6. -25.
## 6 -4. 12.
## 7 -5. 19.
## 8 -3. -14.
## 9 -3. -8.
## 10 -2. 8.
## # ... with 336,766 more rowsselect(flights, contains("ime"))## # A tibble: 336,776 x 6
## dep_time sched_dep_time arr_time sched_arr_time air_time
## <int> <int> <int> <int> <dbl>
## 1 517 515 830 819 227.
## 2 533 529 850 830 227.
## 3 542 540 923 850 160.
## 4 544 545 1004 1022 183.
## 5 554 600 812 837 116.
## 6 554 558 740 728 150.
## 7 555 600 913 854 158.
## 8 557 600 709 723 53.
## 9 557 600 838 846 140.
## 10 558 600 753 745 138.
## # ... with 336,766 more rows, and 1 more variable: time_hour <dttm>Add new variables with mutate()
mutate() adds new columns at the end of your dataset, new columns that are functions of existing columns
flights_sml <- select(flights,
year:day,
ends_with("delay"),
distance,
air_time
)
mutate(flights_sml,
gain = dep_delay - arr_delay,
speed = distance / air_time * 60
)## # A tibble: 336,776 x 9
## year month day dep_delay arr_delay distance air_time gain speed
## <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2013 1 1 2. 11. 1400. 227. -9. 370.
## 2 2013 1 1 4. 20. 1416. 227. -16. 374.
## 3 2013 1 1 2. 33. 1089. 160. -31. 408.
## 4 2013 1 1 -1. -18. 1576. 183. 17. 517.
## 5 2013 1 1 -6. -25. 762. 116. 19. 394.
## 6 2013 1 1 -4. 12. 719. 150. -16. 288.
## 7 2013 1 1 -5. 19. 1065. 158. -24. 404.
## 8 2013 1 1 -3. -14. 229. 53. 11. 259.
## 9 2013 1 1 -3. -8. 944. 140. 5. 405.
## 10 2013 1 1 -2. 8. 733. 138. -10. 319.
## # ... with 336,766 more rows# Note that you can refer to columns that you’ve just created:
mutate(flights_sml,
gain = dep_delay - arr_delay,
hours = air_time / 60,
gain_per_hour = gain / hours
)## # A tibble: 336,776 x 10
## year month day dep_delay arr_delay distance air_time gain hours
## <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2013 1 1 2. 11. 1400. 227. -9. 3.78
## 2 2013 1 1 4. 20. 1416. 227. -16. 3.78
## 3 2013 1 1 2. 33. 1089. 160. -31. 2.67
## 4 2013 1 1 -1. -18. 1576. 183. 17. 3.05
## 5 2013 1 1 -6. -25. 762. 116. 19. 1.93
## 6 2013 1 1 -4. 12. 719. 150. -16. 2.50
## 7 2013 1 1 -5. 19. 1065. 158. -24. 2.63
## 8 2013 1 1 -3. -14. 229. 53. 11. 0.883
## 9 2013 1 1 -3. -8. 944. 140. 5. 2.33
## 10 2013 1 1 -2. 8. 733. 138. -10. 2.30
## # ... with 336,766 more rows, and 1 more variable: gain_per_hour <dbl># If you only want to keep the new variables, use transmute():
transmute(flights,
gain = dep_delay - arr_delay,
hours = air_time / 60,
gain_per_hour = gain / hours
)## # A tibble: 336,776 x 3
## gain hours gain_per_hour
## <dbl> <dbl> <dbl>
## 1 -9. 3.78 -2.38
## 2 -16. 3.78 -4.23
## 3 -31. 2.67 -11.6
## 4 17. 3.05 5.57
## 5 19. 1.93 9.83
## 6 -16. 2.50 -6.40
## 7 -24. 2.63 -9.11
## 8 11. 0.883 12.5
## 9 5. 2.33 2.14
## 10 -10. 2.30 -4.35
## # ... with 336,766 more rowsGrouped summaries with summarise()
# summarise() collapses a data frame to a single row:
summarise(flights, delay = mean(dep_delay, na.rm = TRUE))## # A tibble: 1 x 1
## delay
## <dbl>
## 1 12.6#summarise() is not terribly useful unless we pair it with group_by(). This changes the unit of analysis from the complete dataset to individual groups. Then, when you use the dplyr verbs on a grouped data frame they’ll be automatically applied “by group”. For example, if we applied exactly the same code to a data frame grouped by date, we get the average delay per date:
by_day <- group_by(flights, year, month, day)
summarise(by_day, delay = mean(dep_delay, na.rm = TRUE))## # A tibble: 365 x 4
## # Groups: year, month [?]
## year month day delay
## <int> <int> <int> <dbl>
## 1 2013 1 1 11.5
## 2 2013 1 2 13.9
## 3 2013 1 3 11.0
## 4 2013 1 4 8.95
## 5 2013 1 5 5.73
## 6 2013 1 6 7.15
## 7 2013 1 7 5.42
## 8 2013 1 8 2.55
## 9 2013 1 9 2.28
## 10 2013 1 10 2.84
## # ... with 355 more rowsCombining multiple operations with the pipe
Imagine that we want to explore the relationship between the distance and average delay for each location. Using what you know about dplyr, you might write code like this:
by_dest <- group_by(flights, dest)
delay <- summarise(by_dest,
count = n(),
dist = mean(distance, na.rm = TRUE),
delay = mean(arr_delay, na.rm = TRUE)
)
delay <- filter(delay, count > 20, dest != "HNL")
# It looks like delays increase with distance up to ~750 miles
# and then decrease. Maybe as flights get longer there's more
# ability to make up delays in the air?
ggplot(data = delay, mapping = aes(x = dist, y = delay)) +
geom_point(aes(size = count), alpha = 1/3) +
geom_smooth(se = FALSE)## `geom_smooth()` using method = 'loess' and formula 'y ~ x'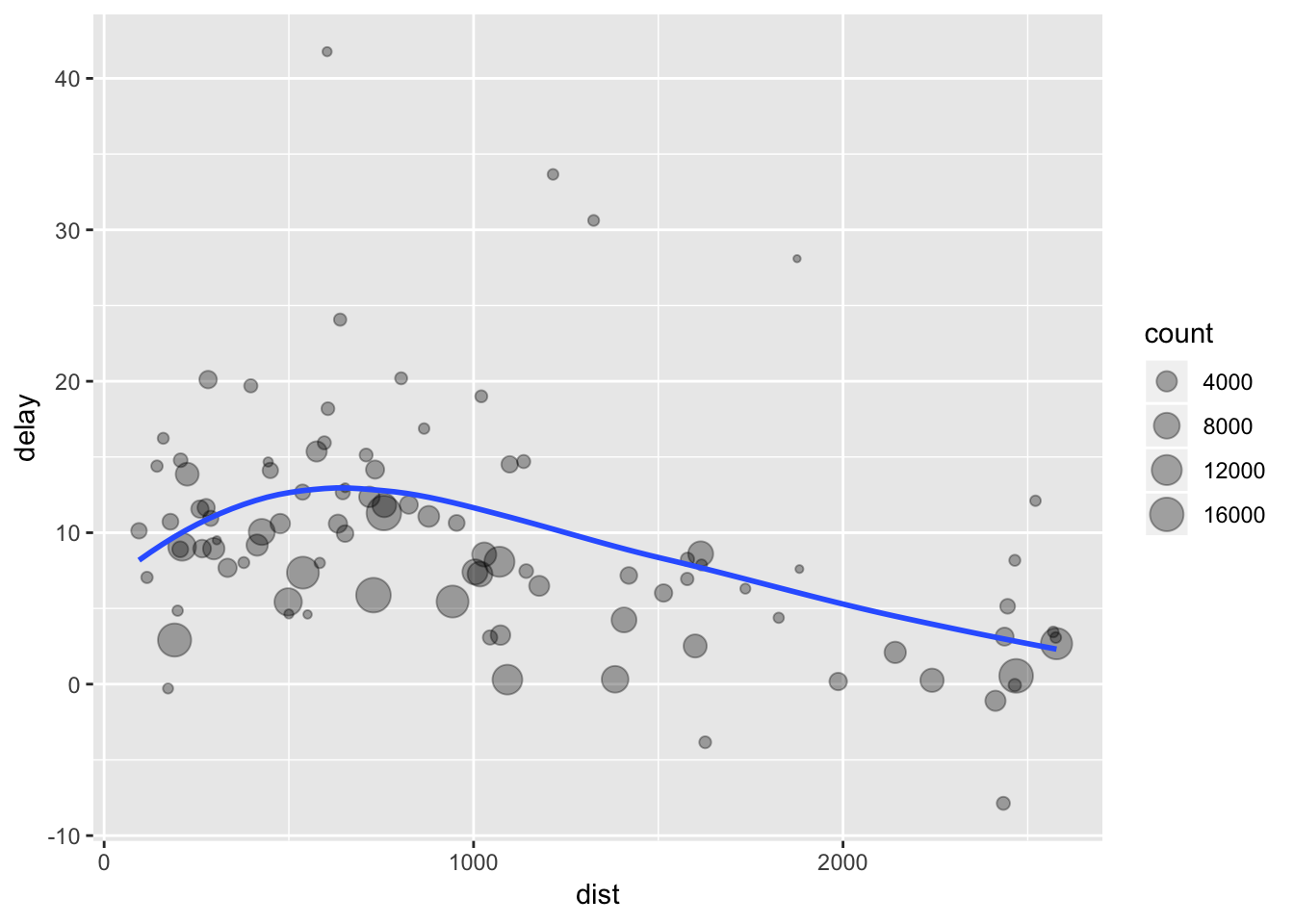 ##### Where missing values represent cancelled flights, we could also tackle the problem by first removing the cancelled flights.
##### Where missing values represent cancelled flights, we could also tackle the problem by first removing the cancelled flights.
not_cancelled <- flights %>%
filter(!is.na(dep_delay), !is.na(arr_delay))
not_cancelled %>%
group_by(year, month, day) %>%
summarise(mean = mean(dep_delay))## # A tibble: 365 x 4
## # Groups: year, month [?]
## year month day mean
## <int> <int> <int> <dbl>
## 1 2013 1 1 11.4
## 2 2013 1 2 13.7
## 3 2013 1 3 10.9
## 4 2013 1 4 8.97
## 5 2013 1 5 5.73
## 6 2013 1 6 7.15
## 7 2013 1 7 5.42
## 8 2013 1 8 2.56
## 9 2013 1 9 2.30
## 10 2013 1 10 2.84
## # ... with 355 more rowsGrouping is most useful in conjunction with summarise(), but you can also do convenient operations with mutate() and filter():
# Find the worst members of each group:
flights_sml %>%
group_by(year, month, day) %>%
filter(rank(desc(arr_delay)) < 10)## # A tibble: 3,306 x 7
## # Groups: year, month, day [365]
## year month day dep_delay arr_delay distance air_time
## <int> <int> <int> <dbl> <dbl> <dbl> <dbl>
## 1 2013 1 1 853. 851. 184. 41.
## 2 2013 1 1 290. 338. 1134. 213.
## 3 2013 1 1 260. 263. 266. 46.
## 4 2013 1 1 157. 174. 213. 60.
## 5 2013 1 1 216. 222. 708. 121.
## 6 2013 1 1 255. 250. 589. 115.
## 7 2013 1 1 285. 246. 1085. 146.
## 8 2013 1 1 192. 191. 199. 44.
## 9 2013 1 1 379. 456. 1092. 222.
## 10 2013 1 2 224. 207. 550. 94.
## # ... with 3,296 more rows# Find all groups bigger than a threshold:
popular_dests <- flights %>%
group_by(dest) %>%
filter(n() > 365)
popular_dests## # A tibble: 332,577 x 19
## # Groups: dest [77]
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2. 830
## 2 2013 1 1 533 529 4. 850
## 3 2013 1 1 542 540 2. 923
## 4 2013 1 1 544 545 -1. 1004
## 5 2013 1 1 554 600 -6. 812
## 6 2013 1 1 554 558 -4. 740
## 7 2013 1 1 555 600 -5. 913
## 8 2013 1 1 557 600 -3. 709
## 9 2013 1 1 557 600 -3. 838
## 10 2013 1 1 558 600 -2. 753
## # ... with 332,567 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm># Standardise to compute per group metrics:
popular_dests %>%
filter(arr_delay > 0) %>%
mutate(prop_delay = arr_delay / sum(arr_delay)) %>%
select(year:day, dest, arr_delay, prop_delay)## # A tibble: 131,106 x 6
## # Groups: dest [77]
## year month day dest arr_delay prop_delay
## <int> <int> <int> <chr> <dbl> <dbl>
## 1 2013 1 1 IAH 11. 0.000111
## 2 2013 1 1 IAH 20. 0.000201
## 3 2013 1 1 MIA 33. 0.000235
## 4 2013 1 1 ORD 12. 0.0000424
## 5 2013 1 1 FLL 19. 0.0000938
## 6 2013 1 1 ORD 8. 0.0000283
## 7 2013 1 1 LAX 7. 0.0000344
## 8 2013 1 1 DFW 31. 0.000282
## 9 2013 1 1 ATL 12. 0.0000400
## 10 2013 1 1 DTW 16. 0.000116
## # ... with 131,096 more rows